


What makes this special?
- Complete Privacy: Your AI assistant runs entirely on your local infrastructure - no data leaves your network
- Persistent Memory: Chroma vector database remembers everything you teach it, creating a truly personalized AI
- Local LLM Power: Ollama runs powerful language models locally, no internet required for AI responses
- Your Data, Your Control: All documents, conversations, and embeddings stored securely on your own storage
- Zero Subscription Costs: Open-source stack with no ongoing fees or usage limits
- Self-Hosted Excellence: Full control over your AI assistant’s capabilities and data retention
How does it work?
- Smart Document Processing: Upload your documents and Chroma automatically creates searchable knowledge
- Intelligent Memory: Your AI remembers past conversations and can reference your uploaded documents
- Local Processing: Everything runs on your hardware - documents, conversations, and AI responses stay private
- Easy Setup: One-command deployment with Docker Compose for hassle-free installation
- Model Flexibility: Choose from various open-source LLM models that run entirely offline
- Real-time Monitoring: Track your AI’s performance and resource usage with built-in dashboards
What you need
- Docker & Docker Compose installed
- 8GB+ RAM (for running AI models locally)
- Basic familiarity with Docker commands
- Your own documents to create a personalized AI knowledge base
Source Code
https://github.com/Lforlinux/Opensource-LLM-RAG-Stack
How to deploy the infrastructure
Quick Start Deployment
|
|
Docker Compose Architecture
|
|
Architecture
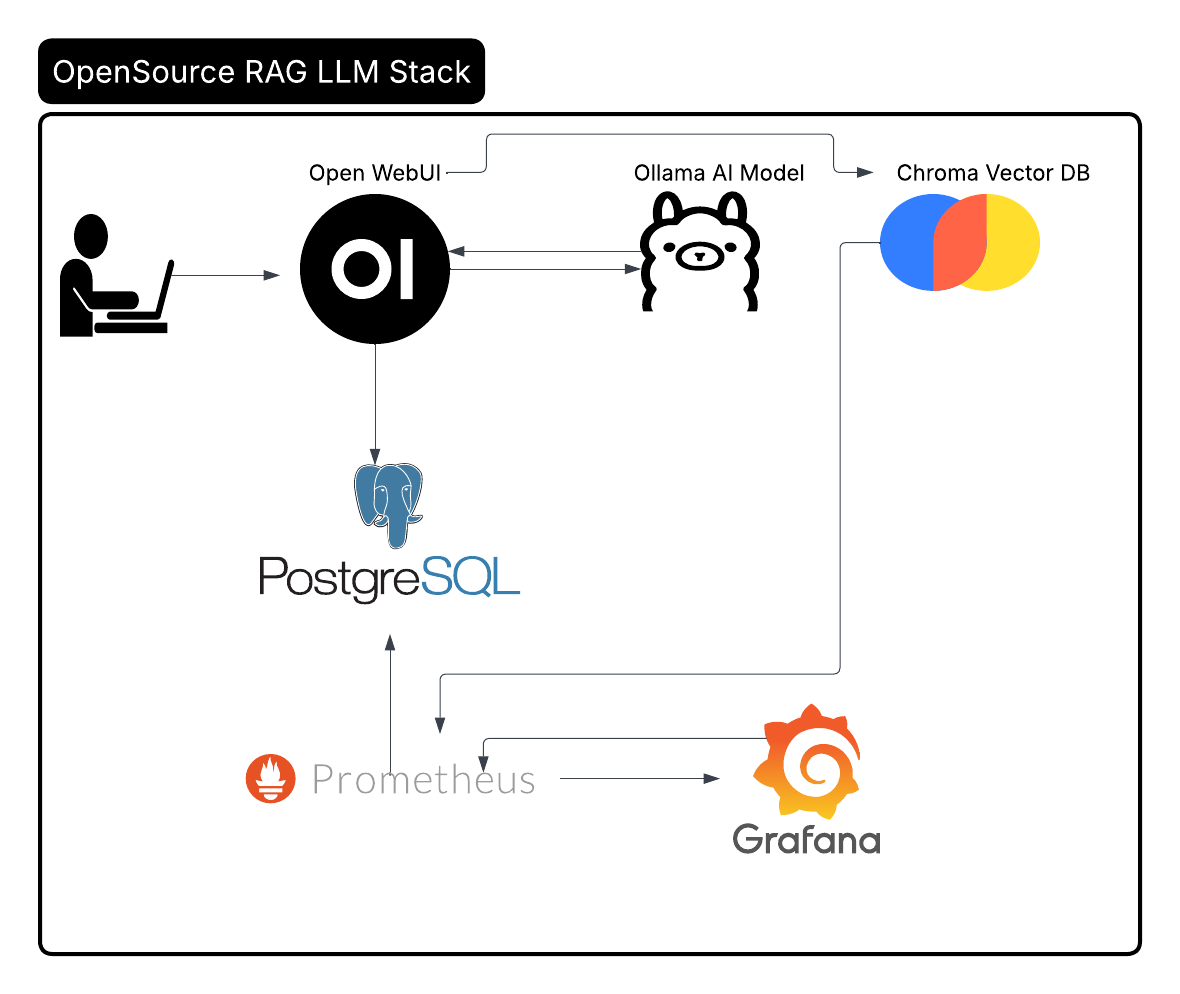
RAG Stack Components
- Open WebUI: User interface for chat interactions and document management
- Ollama: Containerized LLM inference engine with model management
- Chroma: Vector database for semantic search and embeddings storage
- PostgreSQL: Relational database for chat history and document metadata
- Prometheus: Metrics collection and monitoring
- Grafana: Visualization and dashboard management
Key Features
RAG Implementation
- Document Processing: Automatic chunking and embedding generation
- Semantic Search: Vector similarity search for relevant context retrieval
- Context Augmentation: Dynamic prompt enhancement with retrieved information
- Chat History: Persistent conversation management with PostgreSQL
- Model Management: Easy model switching and versioning with Docker volumes
Monitoring & Observability
- Service Health: Real-time monitoring of all stack components
- Performance Metrics: Request rates, response times, and resource usage
- Database Monitoring: PostgreSQL performance and query optimization
- Vector DB Metrics: Chroma collection health and search performance
- Grafana Dashboards: Pre-configured dashboards for comprehensive monitoring
Database Schema & Architecture
PostgreSQL Schema
|
|
RAG Implementation Guide
Document Upload & Processing
- Access Open WebUI: Navigate to http://localhost:3000
- Upload Documents: Support for PDF, TXT, and other formats
- Automatic Processing: System chunks documents and generates embeddings
- Vector Storage: Embeddings stored in Chroma for semantic search
Query with RAG
- User Query: Ask questions in Open WebUI interface
- Context Retrieval: System retrieves relevant chunks from Chroma
- Prompt Augmentation: Retrieved context enhances user prompts
- LLM Generation: Ollama generates responses using augmented context
Monitoring & Observability
Prometheus Metrics
- Service Health:
up{job=~"prometheus|postgres_exporter"} - Database Performance: PostgreSQL exporter metrics
- Request Rates: HTTP request monitoring
- Resource Usage: Container and system metrics
Grafana Dashboards
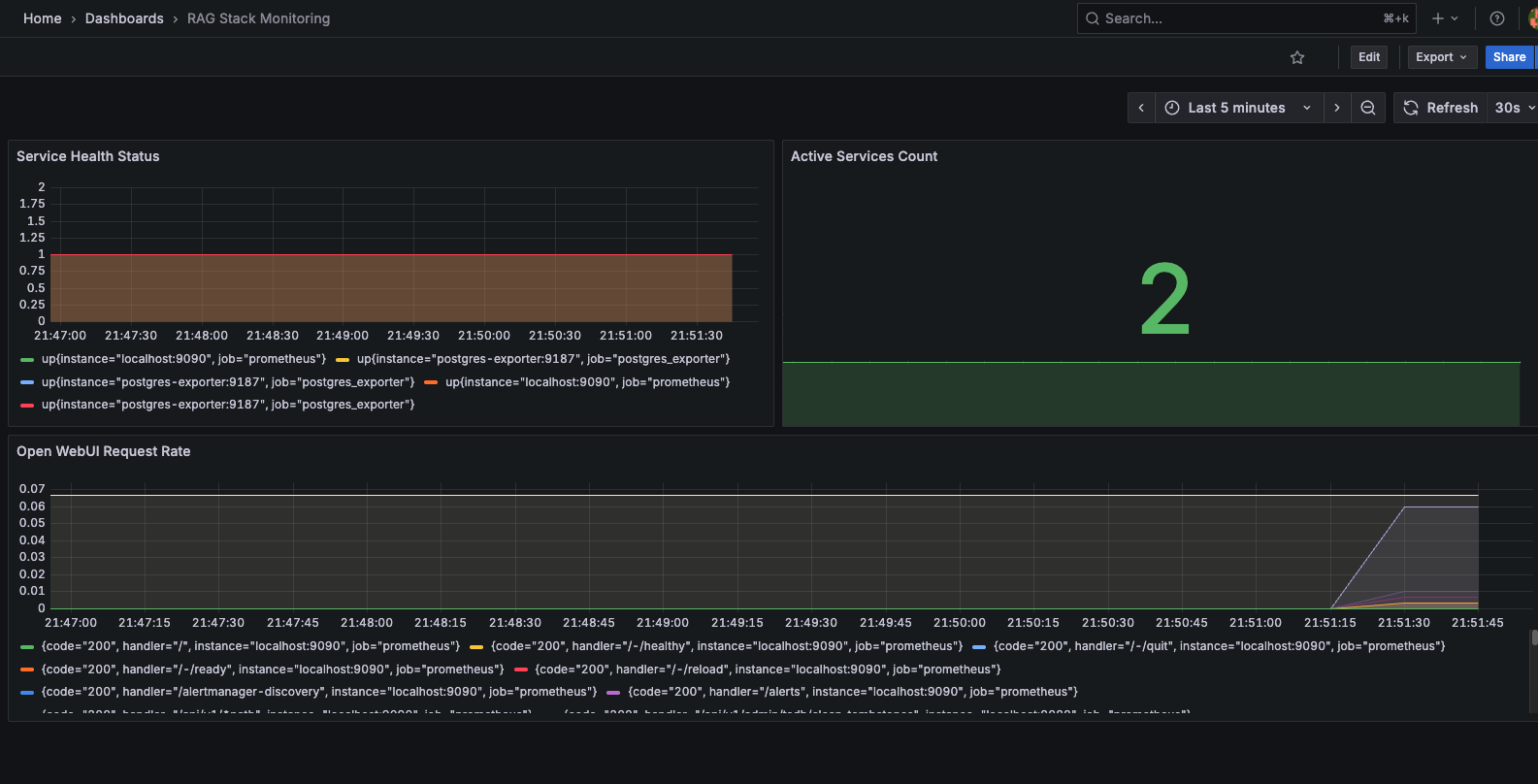
- RAG Stack Overview: Service health and performance
- Database Metrics: PostgreSQL performance monitoring
- System Resources: CPU, memory, and disk usage
- Request Analytics: API call patterns and response times
Production Deployment
Environment Configuration
|
|
Scaling Considerations
- Horizontal Scaling: Multiple Ollama instances behind load balancer
- Database Scaling: PostgreSQL read replicas for query performance
- Vector DB Scaling: Chroma clustering for high availability
- Monitoring: Prometheus federation for multi-instance monitoring
Security Best Practices
Infrastructure Security
- Network Isolation: Container network security and service isolation
- Environment Configuration: Secure environment variable management
- Data Encryption: Encryption at rest and in transit
- Access Control: Proper authentication and authorization
Data Protection
- Backup Strategy: Automated backup for all persistent data
- Data Privacy: No sensitive data logging in production
- Secure Communication: HTTPS/TLS for all service communications
- Container Security: Regular image updates and vulnerability scanning
Troubleshooting
Common Issues
-
RAG Not Working - Document Upload Issues
1 2# Check Chroma connection curl -s -o /dev/null -w "%{http_code}\n" http://localhost:8000/api/v2/heartbeat -
Database Connection Issues
1 2 3 4 5# Check PostgreSQL status docker-compose logs postgres # Verify database initialization docker exec -it postgres psql -U user -d chatdb -c "\dt" -
Model Loading Problems
1 2 3 4 5# Check Ollama service docker-compose logs ollama # Verify model availability curl http://localhost:11434/api/tags
Future Enhancements
Planned Features
- Multi-Model Support: Support for multiple LLM providers
- Advanced RAG: Hybrid search with keyword and semantic matching
- API Integration: RESTful API for external system integration
- Multi-Tenant Support: Isolated environments for different users
Technical Improvements
- High Availability: Multi-instance deployment with load balancing
- Performance Optimization: Query optimization and caching strategies
- Security Hardening: Enhanced authentication and authorization
- Monitoring Enhancement: Advanced alerting and anomaly detection
Contributing
Development Setup
- Fork the repository
- Create feature branch:
git checkout -b feature/your-feature - Make changes and test locally
- Commit changes:
git commit -m "Add your feature" - Push to branch:
git push origin feature/your-feature - Create Pull Request
Code Standards
- Docker: Container optimization and security best practices
- Database: PostgreSQL performance and schema optimization
- Monitoring: Prometheus metrics and Grafana dashboard standards
- Documentation: Clear setup and troubleshooting guides
Conclusion
This OpenSource LLM RAG Stack project demonstrates enterprise-grade AI infrastructure practices, showcasing:
- Production-Ready RAG System with comprehensive monitoring
- Containerized Microservices architecture for scalability
- Vector Database Integration for semantic search capabilities
- Observability with Prometheus and Grafana monitoring
- Enterprise DevOps practices with Infrastructure as Code
The project serves as both a functional RAG system and a comprehensive example of modern AI infrastructure, making it an excellent addition to any AI/ML engineer’s portfolio.
Source Code: https://github.com/Lforlinux/Opensource-LLM-RAG-Stack